

So, you want to learn Data Engineering and looking for Udacity Data Engineer Nanodegree Review?… That’s good. Data Engineering is a popular field nowadays. And there are various resources available online to learn Data Engineering.
The Udacity Data Engineering Nanodegree program is also a popular program. In this article, I will share everything related to the Udacity Data Engineering Nanodegree program.
Note-> This Udacity Data Engineer Nanodegree Review is going to be detailed with respect to the course content and projects. My Aim is to clear everything regarding Udacity Data Engineer Nanodegree. That’s why I would suggest you read all these details before enrolling in the program.
I tried to cover all basic details on projects and course content.
Aqsa Zafar
Udacity Data Engineer Nanodegree Review
- Steps After Enrolling in Udacity Data Engineer Nanodegree
- Udacity Data Engineer Nanodegree Program Structure
- Udacity Data Engineer Nanodegree Projects and Courses
- Unique Features of Udacity Data Engineer Nanodegree
- Drawbacks of Udacity Data Engineer Nanodegree
- Pricing and Duration of Udacity Data Engineer Nanodegree
- Is Udacity Data Engineer Nanodegree Worth It?
- Conclusion
Steps After Enrolling in Udacity Data Engineer Nanodegree
So, let’s start the Udacity Data Engineer Nanodegree Review with the first step of Udacity Data Engineering Nanodegree enrollment. When I enrolled in the program, the first screen was something like that-
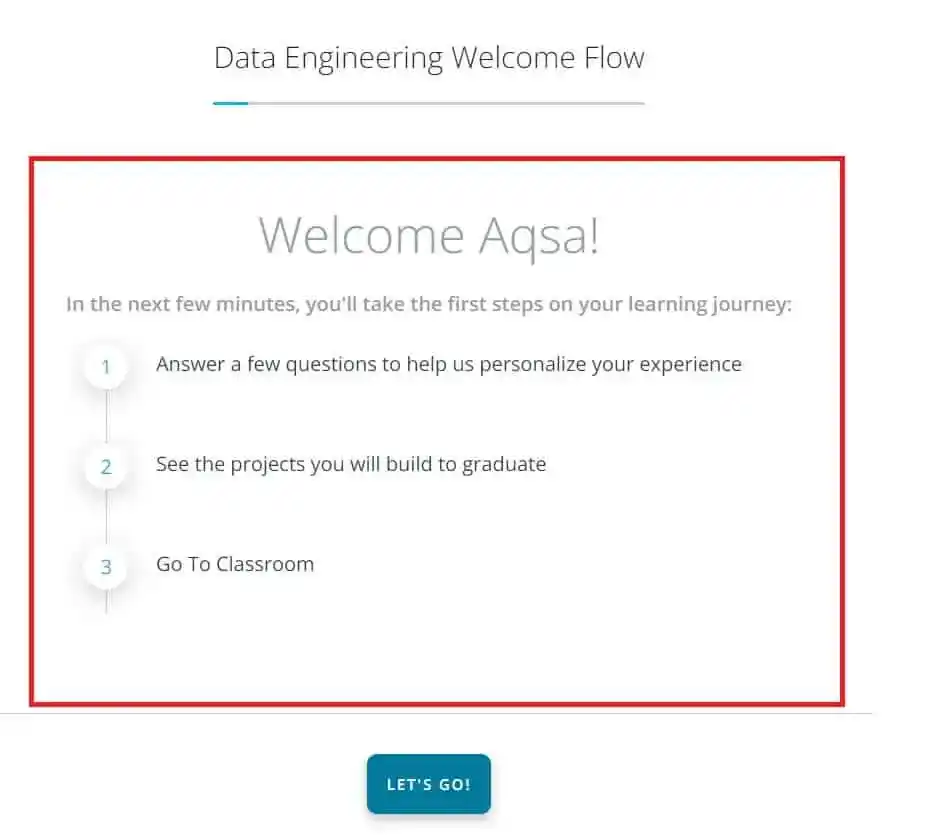
They asked me to answer a few questions and watch the projects and syllabus of the Nanodegree Program. Once I clicked on the “Let’s Go” button, on the next screen, there were some unique features of Udacity listed.
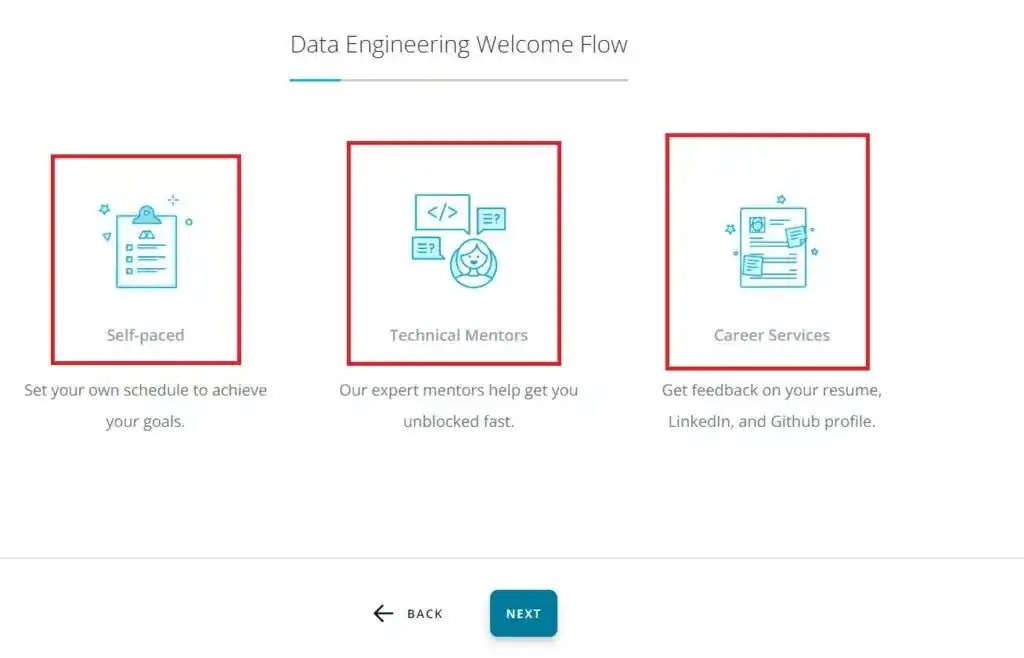
I will talk about these features later in this article. After pressing the “Next Button”, on the next screen, There were 9 questions related to my study plan. I answered all these questions.
In the last step, Udacity showed me the projects covered in this Udacity Data Engineer Nanodegree Program. There are 6 projects in Udacity Data Engineer Nanodegree Program.
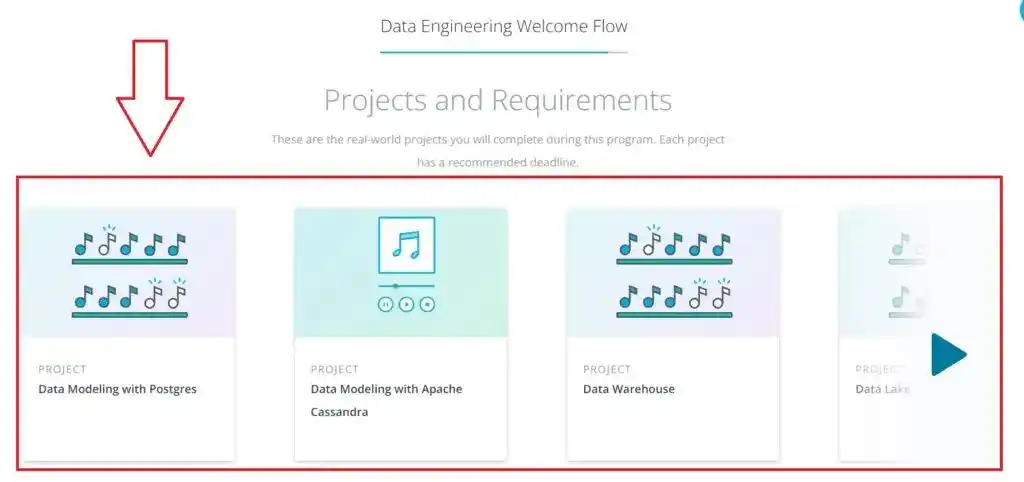
Once I clicked on the “Next” button, on the next screen, they showed me this message.
I clicked on the “Go to Classroom” button. And I was redirected to the Curriculum section.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
Udacity Data Engineer Nanodegree Program Structure
There were 3 sections- Core, Elective, and Career.
In Core, there were 4 courses and 6 projects that I had to complete-
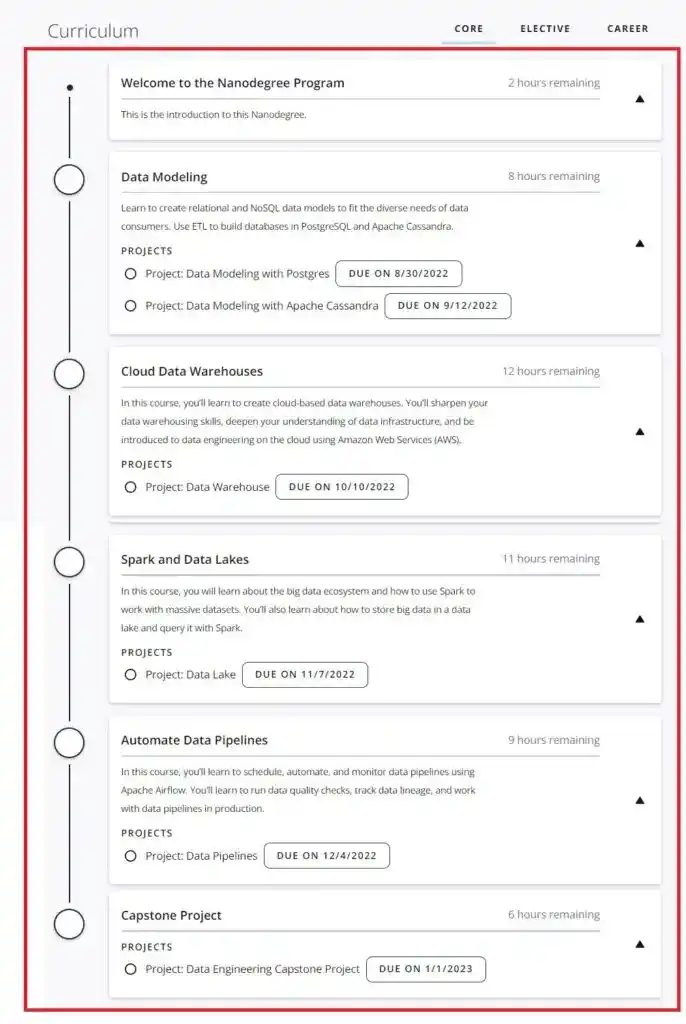
In Elective, there were courses to learn the prerequisites such as Python, SQL, and Command Line Essentials. If you don’t know Python and SQL, then first start with these elective courses.
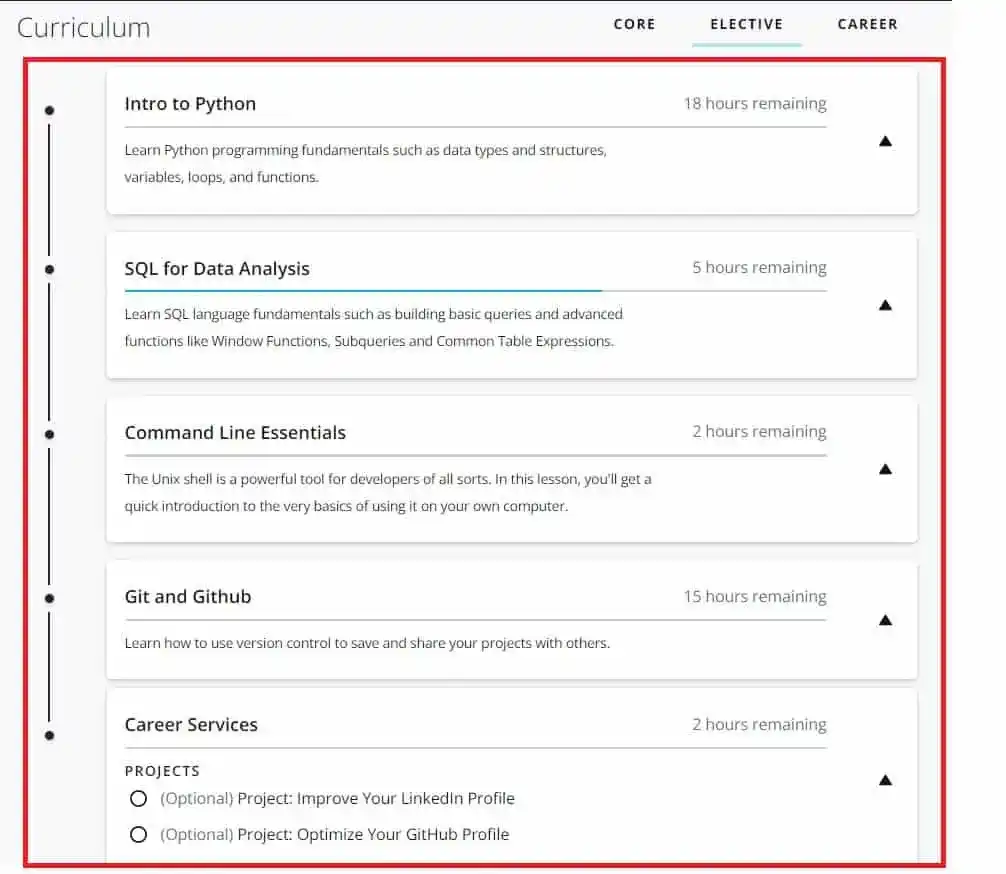
The Best thing I found in Udacity Data Engineer Nanodegree was its extra materials for learning. As you can see, there were extra courses for learning Git and Github.
There was also a separate section for Career Services. In this section, there were two optional projects for creating and improving LinkedIn and GitHub profiles. This helped me to make my profiles more professional.
So, this was the whole Udacity Data Engineer Nanodegree Program structure. Now, let’s see each course and project in detail.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
Udacity Data Engineer Nanodegree Projects and Courses
Course 1- Welcome to the Data Engineering Nanodegree Program
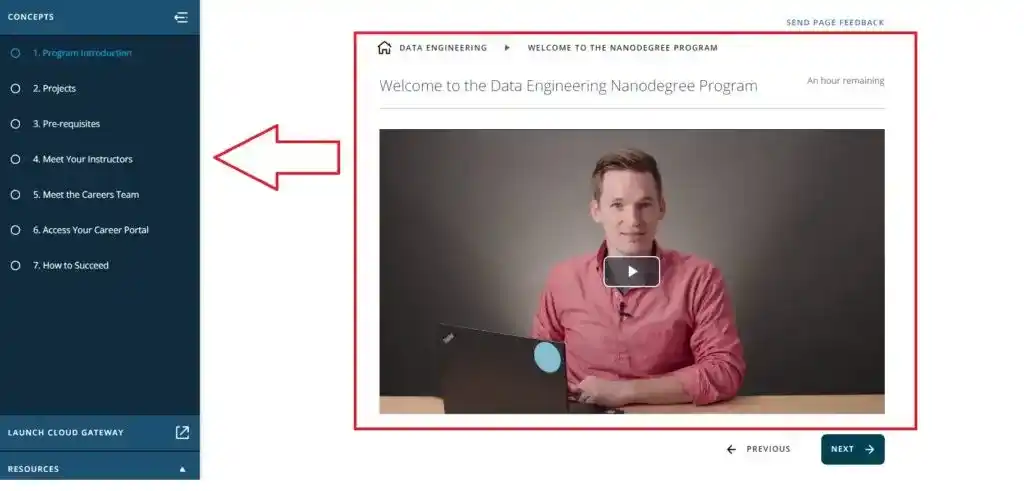
The first course in Udacity Data Engineer Nanodegree was a basic introduction to the Nanodegree Program. Sam Nelson introduced this course. He taught me what is Data Engineering and Why it is used.
After that, he explained what topics and projects will be covered in this Udacity Data Engineer Nanodegree program.
In this course, I also got to know about the projects and prerequisites. Then I met with my instructors, met with the career team, and understood how to access the Career Portal.
I was amazed by Udacity Career Services.
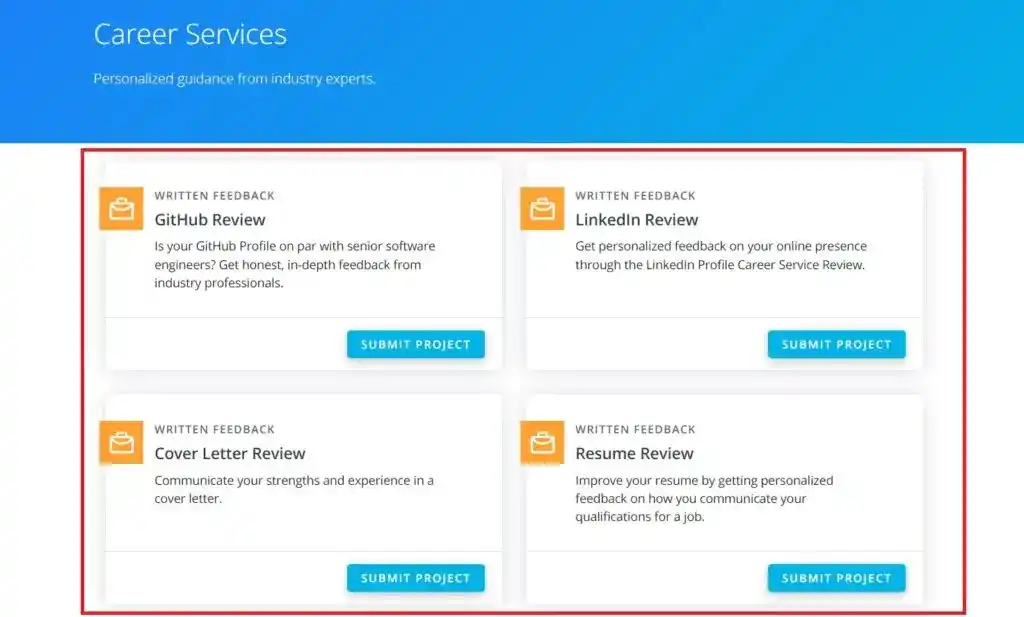
They help in improving GitHub and Linkedin profiles and also provide support for Cover letters and resumes. The last section of this course was What is Data Engineering, Data Engineering Roles and Responsibilities, and Data Engineering Tools.
After completing this course, I moved to the next course.
Course 2- Data Modeling
This was the first course according to Udacity Data Engineer Nanodegree but the introduction course also had enough content for beginners. That’s why I consider this course as the second course.
This course was all about Data Modelling. There were 3 lessons in this course.
In the first lesson, I learned the strengths and weaknesses of various databases and data modeling techniques.
Amanda Moran was the instructor of this course. She is the developer advocate at DATASTAX.
To understand the concepts of Data Modeling, previous knowledge of SQL and Python was required. Without having Python and SQL knowledge, it is hard to excel in this course.
As I discussed before, Udacity provided us with extra elective courses for Python and SQL. So, If you don’t have Python and SQL knowledge, first watch these courses.
Throughout this course, I learned various new concepts such as ACID transactions, PostgreSQL, NoSQL Databases, and Apache Cassandra.
This course also had short quizzes where we had to submit our answers in the form of True or False. The quizzes were for testing the understanding of students.
Amanda was the perfect instructor. She also explained when to use Relational Databases and when not to use Relational Databases.
She also provided a demo for creating a Postgres Table and creating a Table with Cassandra.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
In the next lesson, she explained Modeling Relation Databases. Normalization, Denormalization, Fact/dimension tables and Different schema models were covered in this lesson. She also explained Online Analytical Processing (OLAP) vs Online Transactional Processing (OLTP).
There were 3 demos in this lesson.
Demo 1-> Creating Normalized Table
Demo2-> Creating Denormamlized Table
Demo 3-> Creating Fact and Dimension Table
After completing this course, there were two projects in this course.
Project 1- Data Modeling with Postgres
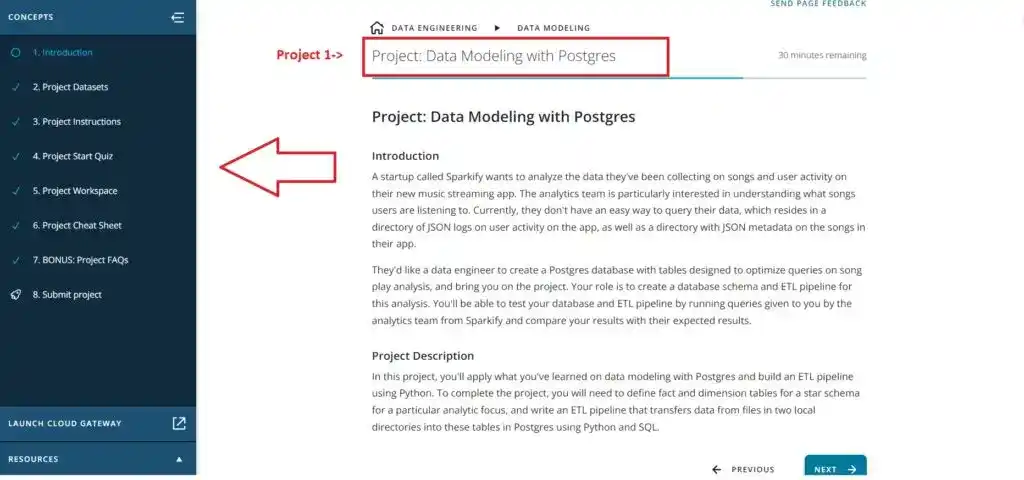
In this project, we had to create a database schema and ETL pipeline for a startup known as Sparkify.
The first dataset was Million Song Dataset. All files were in JSON format and contains metadata about a song and details of the artist.
Udacity provided a Project Rubric where they listed all the criteria and specifications we had to meet.
I would suggest reading the rubric during the project to check whether you are working right or not.
To make the project easier, they also provided a Project Cheatsheet. Throughout the project, a technical mentor was available for solving any doubts. This feature of Udacity was awesome.
Once the project was completed, we had to submit the project in a zip file or Github repo.
According to Udacity, one week was the time to check the project, but they reviewed and approved the project in two days. And I received a mail that my project has been reviewed.
Project 2- Data Modeling with Apache Cassandra
In this project, the same task had to perform using Apache Cassandra. The project objective was the same as project 1.
Only we had to use Apache Cassandra in the place of Postgres.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
After completing these two projects, I moved to the next course.
Course 3- Cloud Data Warehouses
There were 3 lessons in this course. The first course was a basic introduction to data warehouses. The second course was on Cloud Computing and AWS. And the third course was Implementing Datawarehouse on AWS.
Sameh El-Ansary was the instructor of this course. In the first lesson, he covered a Business Perspective of a Data Warehouse, Operational vs Analytical Business Processes, and Dimensional Modeling.
He also provided a demo on various steps in ETL. In the first step, he showed the first actual running transformation from a 3NF application to a star schema.
He used the Sakila sample database. And there was a PostgreSQL version called Pagila.
There were 6 steps in the ETL demo. After that, he explained Kimball’s Bus Architecture, Independent Data Marts, OLAP Cubes, etc. The whole lesson was comprised of various demos and exercises to teach the concepts in a practical way.
In the next lesson, I learned about Cloud Computing and AWS. The instructor explained how to create an IAM role and attach it to the Redshift cluster. She also explained how to create a bucket in Amazon S3.
The last lesson was a combination of the first two lessons. The last lesson covered the implementation of data warehouses on AWS. I also learned Amazon Redshift Technology in this course.
This was not an easy course because lots of new concepts were taught in this course. Previous knowledge of Python and SQL was required to excel in this course.
This course had one project.
Project 3- Data Warehouse
In this project, we had to work for the same startup company Sparkify.
And we had to build an ETL pipeline for a database hosted on Redshift. There were two datasets-
- Song data
- Log data
First, I designed Table Schemas for fact and dimension tables, then build the ETL pipeline, and then documented the process.
At the end of this project, we had to compare our results with Sparkify’s expected results.
The best thing I found in Udacity was personal feedback on projects. The reviewer provided personal feedback on the projects and suggestions for improving the project.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
After this project, I moved to the next course-
Course 4- Spark and Data Lakes
There were 5 lessons in this course that covered the basics of Spark, Data Wrangling with Spark, Spark Clusters with AWS, and Data Lakes.
The courses began with the Spark and Big Data fundamentals.
For this course, previous SQL, Python, and AWS knowledge were required. The AWS concepts were taught in the previous course, that’s why this course was easy for me.
In the first lesson, the instructor taught about Big Data and four key hardware components-> CPU, Memory, Storage, and Network.
I also learned about small, medium, and big data numbers. Hadoop and MapReduce were also covered in this lesson.
The next lesson was Data Wrangling with Spark. This lesson was more practical in nature. Throughout this course, I learned Functional Programming and worked on Procedural Programming exercises.
The instructors explained some very interesting concepts like Pure Functions in the Bread Factory and The Spark DAGs: Recipe for Data.
The next lesson was short and covered how to set up a Spark Cluster using both Local and Standalone Mode. The instructor also explained the process of Installing and Configuring the AWS CLI.
In the next lesson, I learned about Debugging and Optimization. I also learn about Syntax Errors, Code Errors, and Data Errors.
Spark WebUI was also discussed. Spark WebUI is a built-in user interface that we can access from our web browser. Data Skewness and example of Data Skewness were covered in this lesson.
The last lesson was data lakes. There were more quizzes and demos in this lesson on Data lake. Overall, this was a code and practical heavy lesson. As you can see in this screenshot-
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
My mind was frozen after completing this full course. Because digesting a lot of new information is not easy. I would suggest you make notes during the course. I know this is an extra burden but it will help you in the future.
There was one project after this course.
Project 4- Data Lake
This project was related to the concepts learned about Data Lake. Again, we had to work for Sparkify and build an ETL pipeline.
This ETL pipeline had to extract the data from S3 and then process them using Spark. At the end load the data back into S3.
Spark knowledge was required for this project. In the previous course, the instructor taught about Spark, that’s why this was not a tough project.
For this project, first, we had to launch EMR Cluster and Notebook. All the steps were provided by Udacity to launch EMR Cluster and Notebook.
Course 5- Automate Data Pipelines
There were 4 lessons in this course. This course covered Data pipelines, Data quality, etc.
The first lesson covered data pipeline concepts such as Data Validation, Direct Acyclic Graphs (DAG), DAGs in Apache Airflow, and Building DAGs and running them in Airflow.
For this course, we used the following tools-> Jupyter Notebooks, Python 3, Apache Airflow, and Amazon Web Services (AWS).
Ben Goldberg was the instructor of this course. He taught the concepts in a very simple way. His way of teaching was excellent.
He explained DAGs and Data Pipelines, Data Validation, Apache Airflow, Airflow Hooks, etc.
There were various demos and exercises for practical understanding.
Next, he cleared Data Quality and Data Lineage. He also showed us an example of Data Lineage in Airflow.
After that, he showed a demo on Schedules and Backfills in Airflow and Data Partitioning. This lesson was more practical.
The last lesson was Production Data Pipelines. In this lesson, he taught Extending Airflow Hooks & Contrib. There were also a few demos and exercises on Operator Plugins, Task Boundaries, SubDAGs, and Building a Full DAG.
At the end of this lesson, there were some extra resources were provided to explore other data pipeline orchestrators. After this course, there was one project.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
Project 5- Data Pipelines
In this project, we had to create our own custom operators to perform tasks such as staging the data, filling the data warehouse, and running checks on the data as the final step.
The project template was provided. This template contained three major components for the project:
- The dag template
- The operators
- A helper class
For this project, we had to create an IAM User in AWS and a redshift cluster in AWS.
After this project, there was a last Capstone Project.
Project 6- Capstone Project
This was the last project of Udacity Data Engineer Nanodegree.
Udacity gave us the option to choose the project of our choice or follow the Udacity project.
In Udacity provided project, they asked us to work with four datasets to complete the project.
The main dataset had data on immigration to the United States. And the supplementary datasets had data on airport codes, U.S. city demographics, and temperature data.
For choosing the project of our choice, Udacity provided the Project Resources section. In this section, they listed various resources for finding the datasets.
This was the project workspace-
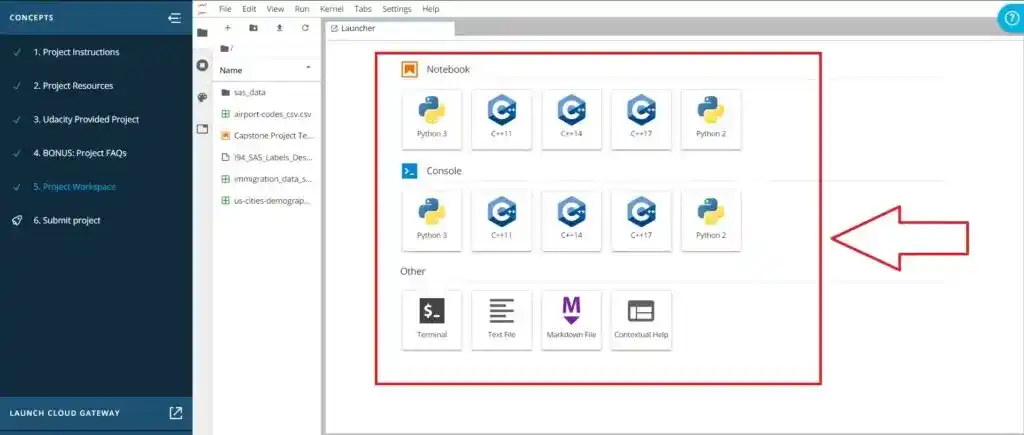
If you ask me to judge Udacity Data Engineer Nanodegree Program on the basis of Projects and Course content, I would say it was the perfect course to learn Data Engineering. The content was comprehensive. Almost all the concepts were covered. Their quizzes and exercise were helpful. All the content were advanced and updated.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
Now, I would like to mention some other features of Udacity Data Engineer Nanodegree, which I liked-
Unique Features of Udacity Data Engineer Nanodegree
Udacity Help and Support
Udacity provides three types of help-
- Technical Mentor Help
- Udacity Support Community
- General Account Help
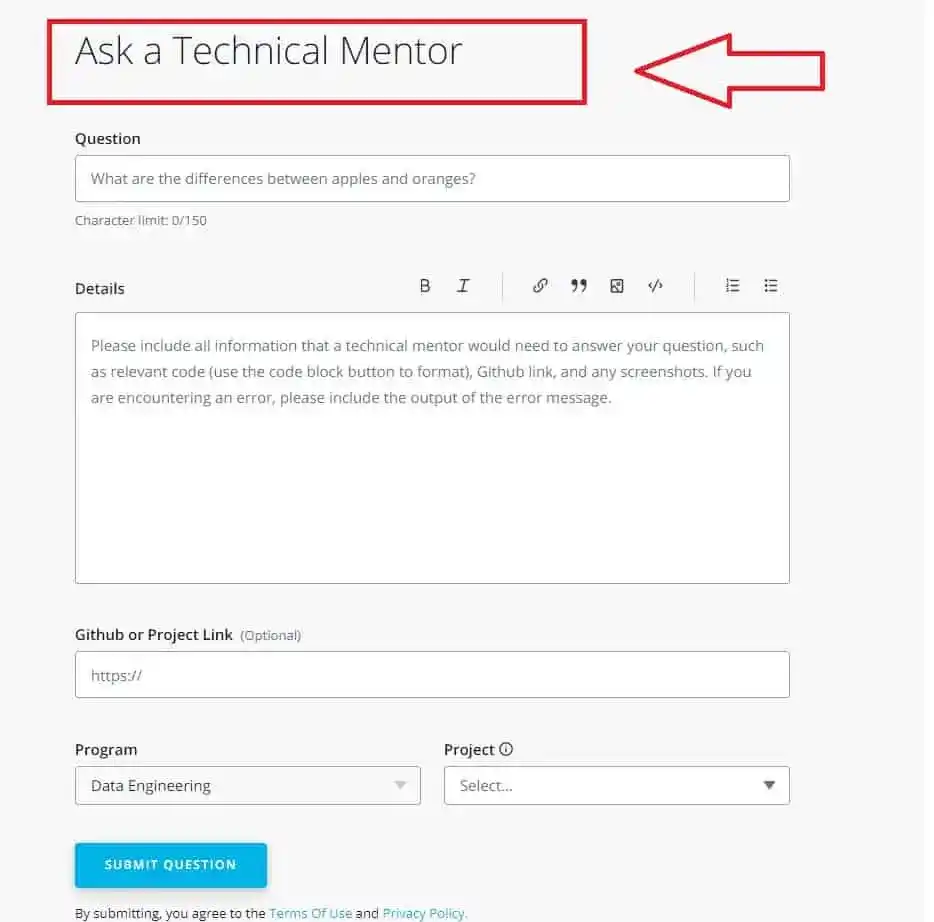
You can ask your question by posting and their technical mentor will answer your questions. Udacity also has a Support Community where you can receive peer support from a global community of learners.
As you can see, you need to write your question with the details such as your program, project, GitHub, or project link. And the mentor will answer your question.
The third help was General Account Help, where you can find details on non-technical issues.
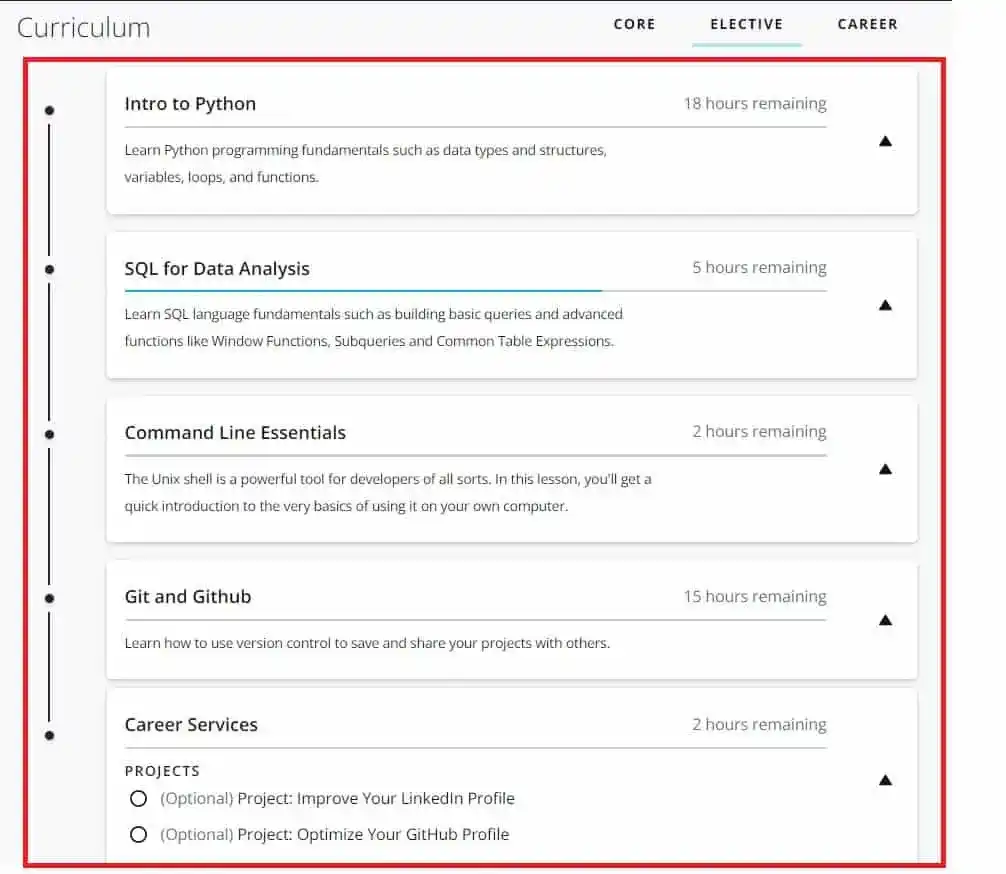
2. Extra Learning Resources
Udacity provides extra elective courses for teaching the prerequisites. For example, in Udacity Data Engineer Nanodegree, Python and SQL knowledge were required. And to learn these skills, Udacity provided elective courses.
This was a unique feature of Udacity which helped many students who can’t afford extra courses.
3. Career Services
Udacity also provides Career Services such as Improving Linkedin profiles and GitHub profiles. There was a separate course on LinkedIn and GitHub profiles.
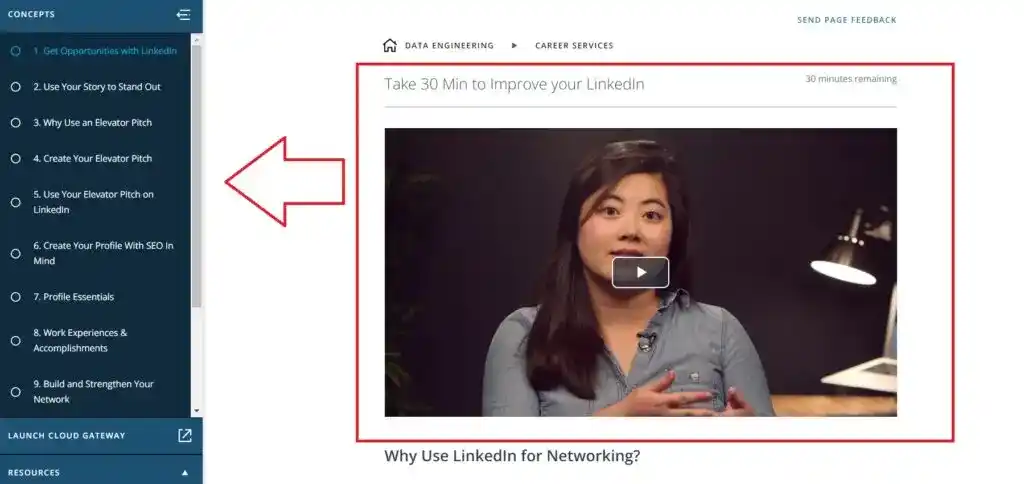
In this 30 min course, they taught how to write your story on Linkedin, how to create your profile with SEO in mind, how to reach out on Linkedin, and how to boost your visibility.
And in GitHub, they taught how to prove your skills using GitHub, what is a Good GitHub repository, how to write READMEs with Walter, how to participate in open source projects, etc.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
So, this is all about the features which I liked about Udacity Data Engineer Nanodegree. Now, I would like to mention what I didn’t like about Udacity Data Engineer Nanodegree.
Drawbacks of Udacity Data Engineer Nanodegree
The only thing which I felt annoying was-
Udacity doesn’t have an Android or IOS APP
Yes, you can’t study on your phone. To complete the Nanodegree Program, every time you have to open your laptop. During this smartphone age, Udacity should create an app for learning.
Sometimes you want to learn according to your comfort and smartphones make learning easier. But this feature was not available in Udacity.
I hope they will launch an app in the future.
Now, let’s see the pricing and time duration of Udacity Data Engineer Nanodegree.
Pricing and Duration of Udacity Data Engineer Nanodegree
Udacity Data Engineer Nanodegree will take 5 months to complete if you weekly spend 5-10 hours. And for 5 months, they cost you around $1200.
I know this is expensive. But most of the time, Udacity is providing offers and discounts. So, you must check for their offers and discount and try to enroll during the discount period.
Check 60% off Discount-> Udacity Data Engineer Nanodegree Program [Use the code BACK2SKILLS]
Check-> Current Udacity Discount
So after reviewing Udacity Data Engineer Nanodegree, it’s time to answer-
Is Udacity Data Engineer Nanodegree Worth It?
Yes, Udacity Data Engineer Nanodegree is worth it for those who know Python and SQL. The content of this Nanodegree program is updated and covers advanced topics in Data Engineering. There are various quizzes and hands-on projects. The technical mentor support feature is helpful. Overall, Udacity Data Engineer Nanodegree is worth it Nanodegree Program.
But without having Python and SQL knowledge, I would not suggest you start learning this Udacity Data Engineer Nanodegree. Perhaps I will recommend you to start off with Programming for Data Science with Python. The Programming for Data Science with Python Nanodegree program is suitable for beginners who want to start their journey in Data Science from scratch.
Now, Udacity Data Engineer Nanodegree Review ends-
Conclusion
I hope this Udacity Data Engineer Nanodegree Review helped you to know better about Udacity Data Engineer Nanodegree Program. If you have any doubts, feel free to ask me in the comment section.
Happy Learning!
You May Also Be Interested In
10 Best Online Courses for Data Science with R Programming
8 Best Free Online Data Analytics Courses You Must Know in 2026
Data Analyst Online Certification to Become a Successful Data Analyst
8 Best Books on Data Science with Python You Must Read in 2026
14 Best+Free Data Science with Python Courses Online- [Bestseller 2026]
10 Best Online Courses for Data Science with R Programming in 2026
8 Best Data Engineering Courses Online- Complete List of Resources
Best Course on Statistics for Data Science to Master in Statistics
8 Best Tableau Courses Online– Find the Best One For You!
8 Best Online Courses on Big Data Analytics You Need to Know
Best SQL Online Course Certificate Programs for Data Science
7 Best SAS Certification Online Courses You Need to Know
Thank YOU!
Explore More about Data Science, Visit Here
Though of the Day…
‘ It’s what you learn after you know it all that counts.’
– John Wooden

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.