Today, I want to talk to you about something important in machine learning: Why Linear Regression Cannot Be Used for Classification. If you’re just starting out, it can be confusing to know when to use certain algorithms. So, let me break it down for you in simple terms and show you why linear regression, which works great for some tasks, doesn’t really fit when you’re dealing with classification problems.
By the end of this, you’ll have a clear understanding of why we need other methods for classification.
So, without any further ado, let’s get started-
Why Linear Regression Cannot Be Used for Classification
What is Linear Regression?
First, let’s talk about linear regression. Linear regression is a way to make predictions when your target (the thing you want to predict) is a number. For example, if you’re predicting house prices, temperature, or sales numbers, linear regression is your friend.
How Linear Regression Works
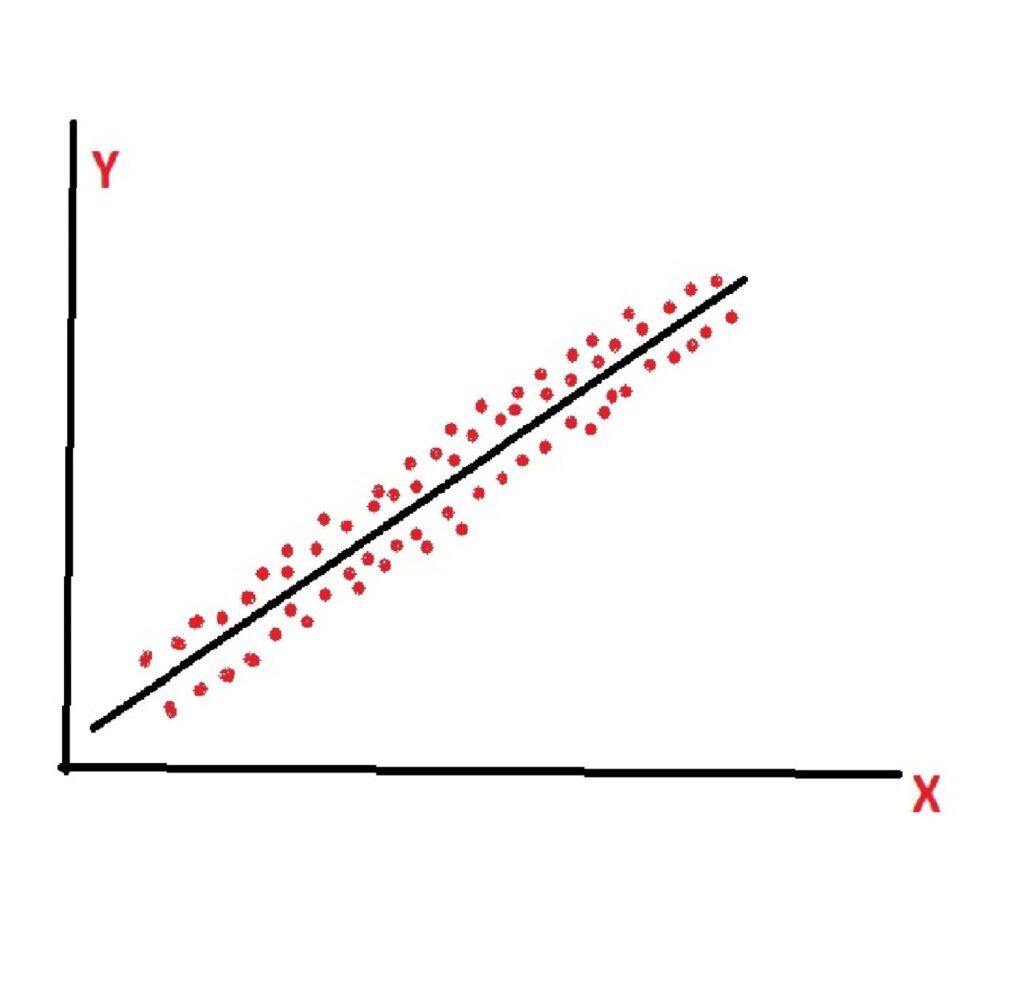
In linear regression, we try to draw a straight line that best fits the data points we have. Imagine you have some dots on a graph (those dots are your data points), and you try to draw a line that’s as close as possible to all the dots. The formula for this line looks like this:
Y=mX+b
Where:
- Y is the target value (what you want to predict)
- X is the input feature (the thing you know)
- m is the slope of the line
- b is the intercept (where the line crosses the Y-axis)
Linear regression is great when you want to predict continuous values like height, weight, or prices.
Example in Python
This is a simple example of linear regression using Python and the Scikit-Learn library:
from sklearn.linear_model import LinearRegression
import numpy as np
# Sample data (X = input, y = target values)
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 5, 4, 5])
# Create a linear regression model
model = LinearRegression()
# Train the model
model.fit(X, y)
# Make predictions
predictions = model.predict(X)
print("Predicted values:", predictions)
What is Classification?
Now, let’s talk about classification. In classification problems, you’re not predicting numbers. Instead, you’re trying to put things into categories or classes. For example, let’s say you want to figure out if an email is spam or not spam. That’s a classification problem because there are only two possible answers (classes): “spam” or “not spam”.
Types of Classification Problems
There are different types of classification problems. Let me quickly explain a few:
- Binary classification: This is when there are only two possible outcomes (like spam vs. not spam).
- Multiclass classification: This is when there are more than two outcomes. For example, you might want to classify a type of flower as setosa, versicolor, or virginica.
- Multilabel classification: This is when each instance can belong to more than one class. For example, a movie could belong to both the “comedy” and “action” genres at the same time.
The Difference Between Regression and Classification
To make things clearer, let’s compare regression and classification:
- Regression predicts continuous values (e.g., predicting a price).
- Classification predicts discrete categories (e.g., predicting if an email is spam or not).
Or you can say:
- In regression, you’re working with numbers.
- In classification, you’re working with labels or categories.
Why Linear Regression Fails in Classification
So, why can’t we just use linear regression to solve classification problems? There are several reasons, and I’ll explain them in simple terms.
Problem with Output Values
Linear regression predicts any number on a continuous scale. But in classification, you only want specific categories. For example, if you’re trying to classify whether an email is spam (1) or not spam (0), linear regression might predict something like 0.6 or -1.2. These values don’t make sense because we need the result to be either 0 or 1 (spam or not spam), not some number in between.
Example: Incorrect Predictions from Linear Regression
# Binary classification problem
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 0, 1, 1, 1]) # Classification labels (binary: 0 or 1)
# Linear Regression for classification (not ideal)
model = LinearRegression()
model.fit(X, y)
predictions = model.predict(X)
print("Predicted values:", predictions)
This code will give us predictions that aren’t exactly 0 or 1, but values like 0.3 or 1.2, which aren’t valid for classification tasks.
Poor Boundaries for Class Separation
When using linear regression for classification, it tries to draw a straight line to separate the classes. However, real-life classification problems are often more complex. The line that separates classes (called a decision boundary) may not be straight. Linear regression just doesn’t handle this complexity well, which means it doesn’t do a good job at separating classes.
Sensitivity to Outliers
Linear regression is very sensitive to outliers (data points that are far from others). In classification, you might have a few unusual points in your data, and linear regression can be easily affected by them, leading to poor predictions.
Probabilities vs. Categories
Another issue is that classification often deals with probabilities. You might want to know how likely it is that an email is spam. Linear regression doesn’t naturally give you probabilities. It just gives you a number, which doesn’t help much when you want to know how confident you are in your prediction.
Alternatives to Linear Regression for Classification
Now that we know why linear regression isn’t a good fit for classification, what should we use instead? Luckily, there are some great algorithms that are specifically designed for classification.
Logistic Regression
Logistic regression is one of the most popular methods for classification. Even though it has “regression” in the name, it’s used for classification tasks. Here’s how it works:
- Instead of predicting a continuous number, logistic regression predicts the probability that something belongs to a certain class.
- It uses a special function (called the sigmoid function) to convert its output into a value between 0 and 1, which can be used for binary classification.
Sigmoid Function:
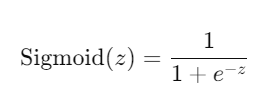
This is a Python example using logistic regression for binary classification:
from sklearn.linear_model import LogisticRegression
# Binary classification data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([0, 0, 1, 1, 1])
# Logistic Regression model
log_reg = LogisticRegression()
log_reg.fit(X, y)
# Predictions
predictions = log_reg.predict(X)
print("Predicted labels:", predictions)
Decision Trees
Decision trees are another good option. They work by splitting the data into smaller and smaller groups, based on the features of the data. At the end, the tree gives you a decision based on these splits (e.g., “spam” or “not spam”).
Random Forest
Random forests are like decision trees, but better! Instead of just one tree, random forests create many trees and combine their decisions. This usually gives you a more accurate result.
Support Vector Machines (SVM)
SVMs are powerful algorithms that try to find the best line (or hyperplane) that separates different classes. They can work with both linear and non-linear boundaries, making them useful for complex classification tasks.
Neural Networks
For more complex classification tasks, especially when you have a lot of data, neural networks are a great option. They’re used in deep learning and can handle very complex patterns.
Best FREE Statistics Courses
| S/N | Course Name | Rating | Time to Complete |
|---|---|---|---|
| 1. | Intro to Statistics– Udacity (FREE Course) | NA | 2 Months |
| 2. | Statistics with R Specialization– Duke University (Coursera) | 4.6/5 | 7 Months |
| 3. | Practical Statistics– Udacity | 4.7/5 | 35 hours |
| 4. | Statistics with Python Specialization– University of Michigan (Coursera) | 4.5/5 | 3 months |
| 5. | Statistician with R– Datacamp | NA | 108 hours |
| 6. | Introduction to Statistics– Coursera (FREE Course) | 4.5/5 | 15 hours |
| 7. | Data Science: Statistics and Machine Learning Specialization– Johns Hopkins University (Coursera) | 4.4/5 | 5 Months |
| 8. | Statistics Fundamentals with R– Datacamp | NA | 20 hours |
| 9. | Statistical Analysis with R for Public Health Specialization– Imperial College London (Coursera) | 4.7/5 | 4 Months |
| 10. | Basic Statistics– University of Amsterdam (Coursera) | 4.7/5 | 26 Hours |
| 11. | Statistics Fundamentals with Python– Datacamp | NA | 19 hours |
| 12. | Learn Statistics with Python– Codecademy | NA | 15 hours |
| 13. | Intro to Inferential Statistics– Udacity (FREE Course) | NA | 2 Months |
| 14. | Intro to Descriptive Statistics– Udacity (FREE Course) | NA | 2 Months |
| 15. | Introduction to Bayesian Statistics– Udemy (FREE Course) | 4.8/5 | 1hr 19min |
I hope now you understand “Why Linear Regression Cannot Be Used for Classification?”. Now, it’s time to wrap up this article.
Conclusion
In this article, I aimed to answer your question: Why Linear Regression Cannot Be Used for Classification. I hope this guide helps you get started on your journey. If you have any doubts or questions, don’t hesitate to ask me in the comment section!
All the Best!
Enjoy Learning!
You May Also Be Interested In
10 Best Online Courses for Data Science with R Programming
8 Best Free Online Data Analytics Courses You Must Know in 2026
Data Analyst Online Certification to Become a Successful Data Analyst
8 Best Books on Data Science with Python You Must Read in 2026
14 Best+Free Data Science with Python Courses Online- [Bestseller 2026]
10 Best Online Courses for Data Science with R Programming in 2026
8 Best Data Engineering Courses Online- Complete List of Resources
Thank YOU!
To explore More about Data Science, Visit Here
Though of the Day…
‘ It’s what you learn after you know it all that counts.’
– John Wooden

Written By Aqsa Zafar
Aqsa Zafar is a Ph.D. scholar in Machine Learning at Dayananda Sagar University, specializing in Natural Language Processing and Deep Learning. She has published research in AI applications for mental health and actively shares insights on data science, machine learning, and generative AI through MLTUT. With a strong background in computer science (B.Tech and M.Tech), Aqsa combines academic expertise with practical experience to help learners and professionals understand and apply AI in real-world scenarios.